학위논문 요약
by 권 진영 (gc757489@gmail.com)
AI 워크로드를 위한 스토리지 중심 컨테이너 배포 스케줄링
1. 가상화 기반 쿠버네티스 환경에서 자원 인지형 동적 스케줄링 및 I/O 대역폭 최적화 기법
1. 연구 배경 및 문제 정의
AI 워크로드는 대규모 모델 파일, 반복적인 전처리 데이터, 배치 단위 입력 데이터로 인해 I/O 집중적 특성을 가진다. 그러나 기존 쿠버네티스 스케줄러는 다음과 같은 구조적 한계를 가진다.
• 파드 배포 시 CPU, 메모리 위주의 정적 자원 정보만 고려 • 스토리지 I/O 대역폭, 데이터 접근 패턴, GPU 자원 병목 등을 고려하지 않음 • 가상머신 하이퍼바이저 계층의 자원 제어 기능과 분리되어 동작
이로 인해 GPU 할당 이후에도 데이터 로딩 지연으로 GPU가 유휴 상태에 놓이는 현상이 반복적으로 발생한다. AI워크로드에서는 고성능 GPU 자원의 활용률 저하와 전체 수행 시간 증가로 직결된다.
• AI 워크로드별 I/O 병목과 수행 시간 차이
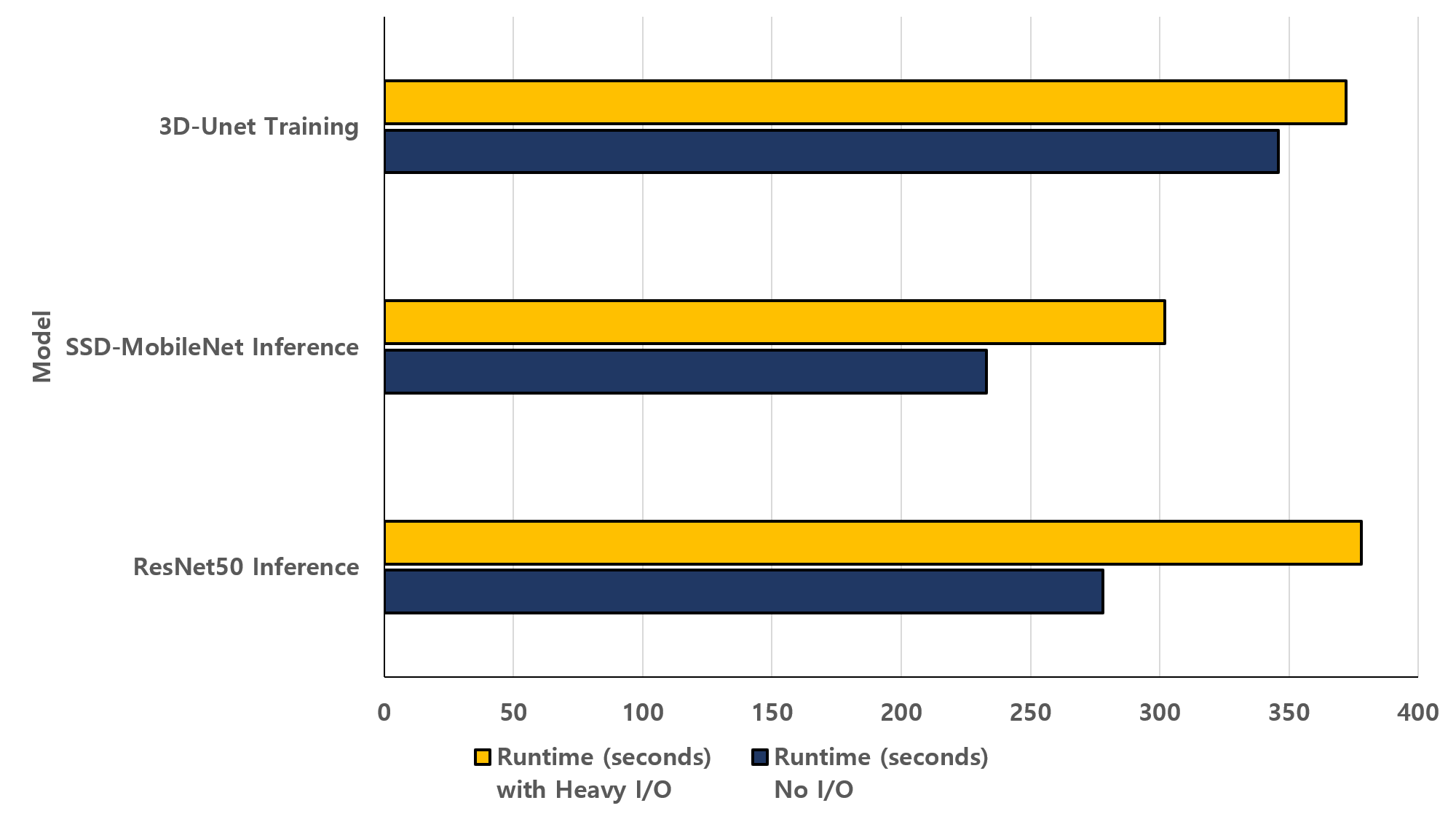 그림 1. AI 워크로드별 I/O 병목에 따른 수행 시간 비교
그림 1. AI 워크로드별 I/O 병목에 따른 수행 시간 비교
그림 1은 3D-Unet, SSD-MobileNet, ResNet50 모델을 대상으로 I/O 병목 상황에서의 수행 시간 증가를 측정한 결과이다. I/O 부하가 없는 정상 상태 대비 I/O 병목 상태에서 각 모델의 수행 시간이 5%에서 25%까지 증가한다. GPU가 초당 수십 테라플롭스의 연산 성능을 제공하더라도, 입력 데이터가 제때 공급되지 못할 경우 대기 상태에 머물게 되어 전체 처리 시간이 증가하는 구조적 문제가 있다.
• I/O 병목에 따른 처리량 차이
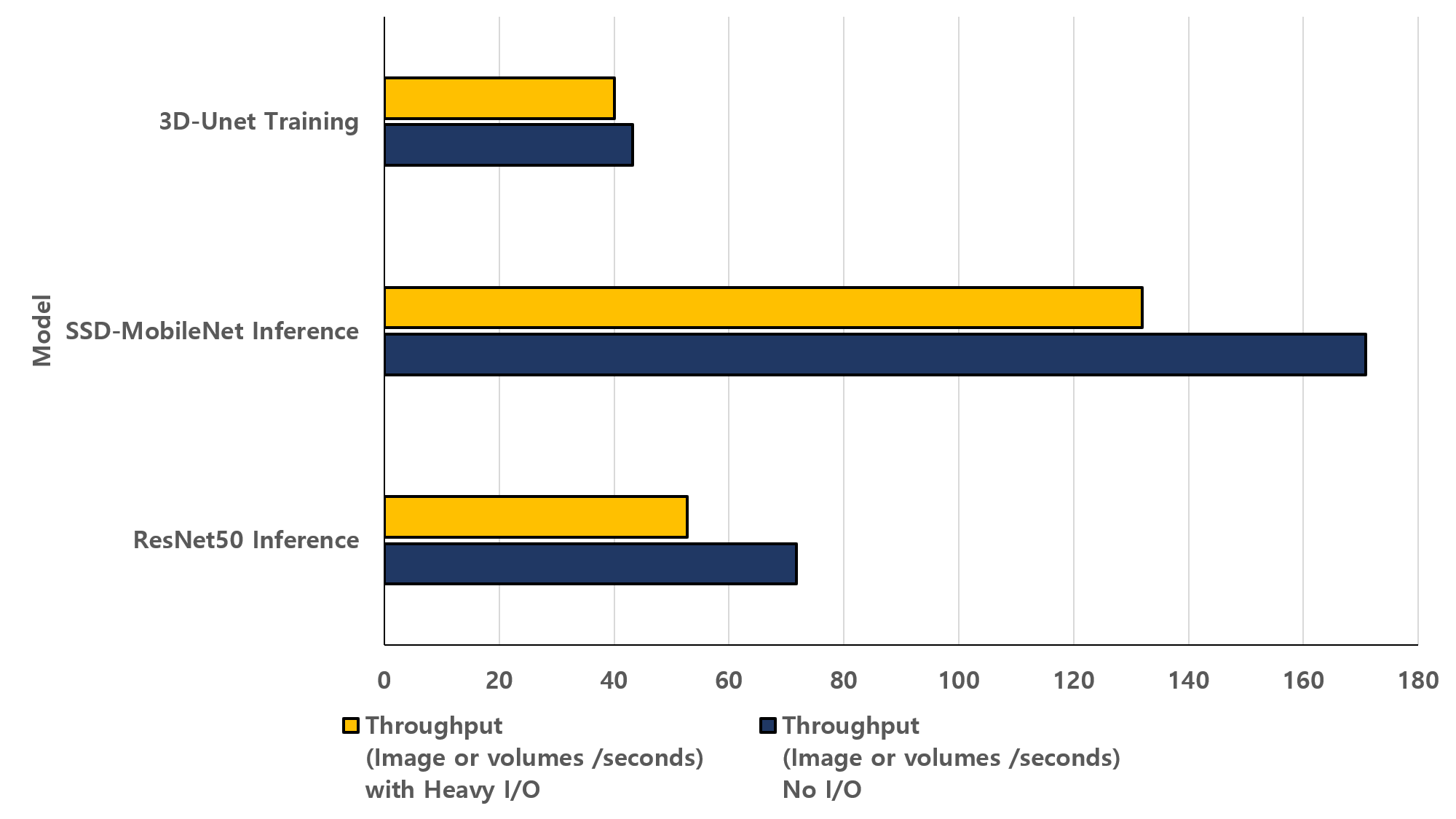 그림 2. AI 워크로드별 I/O 병목에 따른 처리량 비교
그림 2. AI 워크로드별 I/O 병목에 따른 처리량 비교
그림 2는 단위 시간당 처리 가능한 이미지 및 볼륨 수를 보여준다. I/O 부하 상황에서 처리량이 크게 감소한다. 스토리지 I/O 성능이 GPU 활용률의 핵심 제약 요소임을 확인할 수 있다.
2. 시스템 분석
본 연구는 쿠버네티스 및 가상화 환경을 다층적으로 분석하여 다음 문제를 도출한다.
• 쿠버네티스 스케줄링은 배포 시점에 실제 스토리지 부하 상태를 반영하지 못함 • 하이퍼바이저 계층에서는 다수의 가상머신이 동일한 디스크 자원에 접근하며 자원 간섭 발생 • AI 워크로드는 GPU 연산 이전에 대량의 스토리지 읽기 작업을 선행적으로 요구
이 분석을 통해, 배포 이전 단계에서 스토리지 및 GPU 연관 자원 상태를 함께 고려하는 스케줄링의 필요성을 제기한다.
2.1 제안 기법 개요
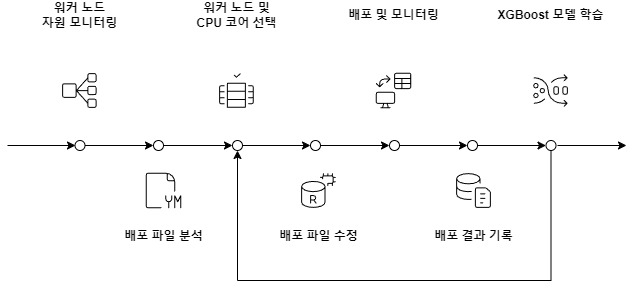 그림 3. 전체 구조 흐름도
그림 3. 전체 구조 흐름도
- 워커 노드 자원 모니터링은 CPU, GPU, 메모리, 스토리지 I/O의 실시간 사용률을 수집
- 배포 파일 분석에서는 모델 종류, 프레임워크 유형, 요청 자원량을 추출
- XGBoost 모델을 통해 최적의 워커 노드와 CPU 코어를 선택
- 배포 파일을 수정
- 실제 배포 및 모니터링을 수행
- 배포 결과를 기록
- XGBoost 모델을 재학습하여 예측 정확도를 지속적으로 향상
이 구조는 정적 정보와 동적 정보를 함께 반영하는 순환형 스케줄링 구조를 가진다.
 그림 6. 자원 예측 및 배포 파일 재작성
그림 6. 자원 예측 및 배포 파일 재작성
자원 예측 단계에서는 배포 파일에서 추출된 정적 피처(프레임워크, 모델, 워크로드 타입 등)와 실시간 모니터링 정보(CPU 사용률, GPU 사용률, I/O 처리량 등)를 XGBoost 모델의 입력으로 사용한다. 모델은 CPU 사용량, GPU 사용량, 메모리 사용량, I/O 사용량을 예측하고, 이를 쿠버네티스 배포 파일 형식으로 변환하여 requests와 limits 항목을 재작성한다.
 그림 7. 배포 결과 모니터링 및 재학습
그림 7. 배포 결과 모니터링 및 재학습
배포 후 실행 과정에서 CPU 사용률, GPU 메모리 소모량, GPU 사용률, 스토리지 처리량이 지속적으로 수집되며, 배포 실패 시 원인도 함께 기록한다. 데이터베이스에 저장된 데이터는 다음 배포에서 자원 보정에 활용되는 학습 데이터로 사용한다. 여러 번 실행될수록 자원 사용 패턴에 대한 예측 정확도를 향상시킨다.
4. 실험 환경
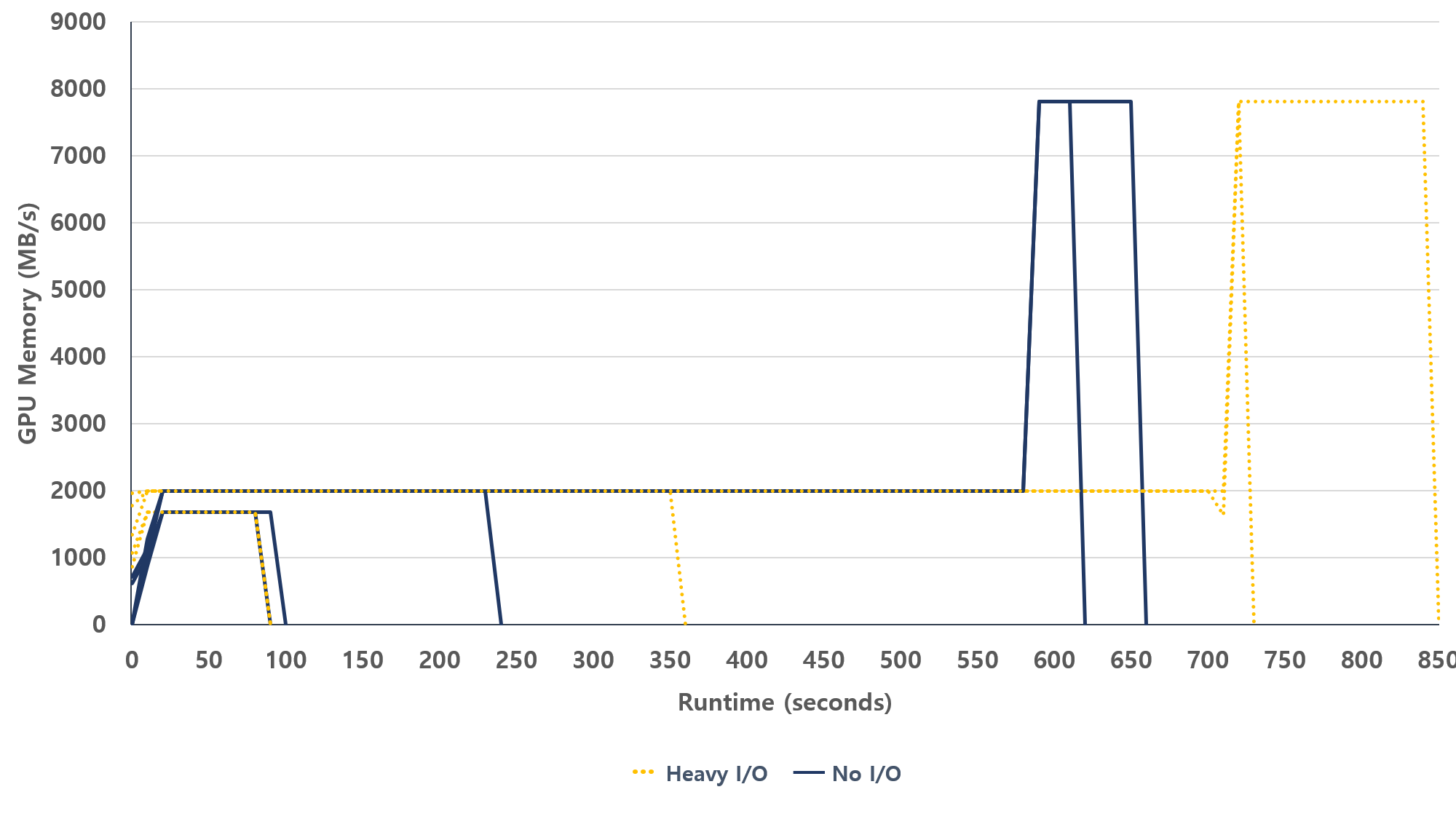 그림 8. I/O 부하 상황에서 다중 파드 배포 후 GPU 메모리 사용률
그림 8. I/O 부하 상황에서 다중 파드 배포 후 GPU 메모리 사용률
그림 8은 여러 파드가 동시에 배포될 때 I/O 부하가 GPU 메모리 점유율에 미치는 영향을 보여주는 그림이다. I/O 부하가 가중되면 가상머신의 I/O 처리량이 포화되며, 각 파드가 GPU에 접근하기 위한 입력 데이터 준비 시간이 늘어나고 수행시간도 늘어난다.
5. 실험 결과
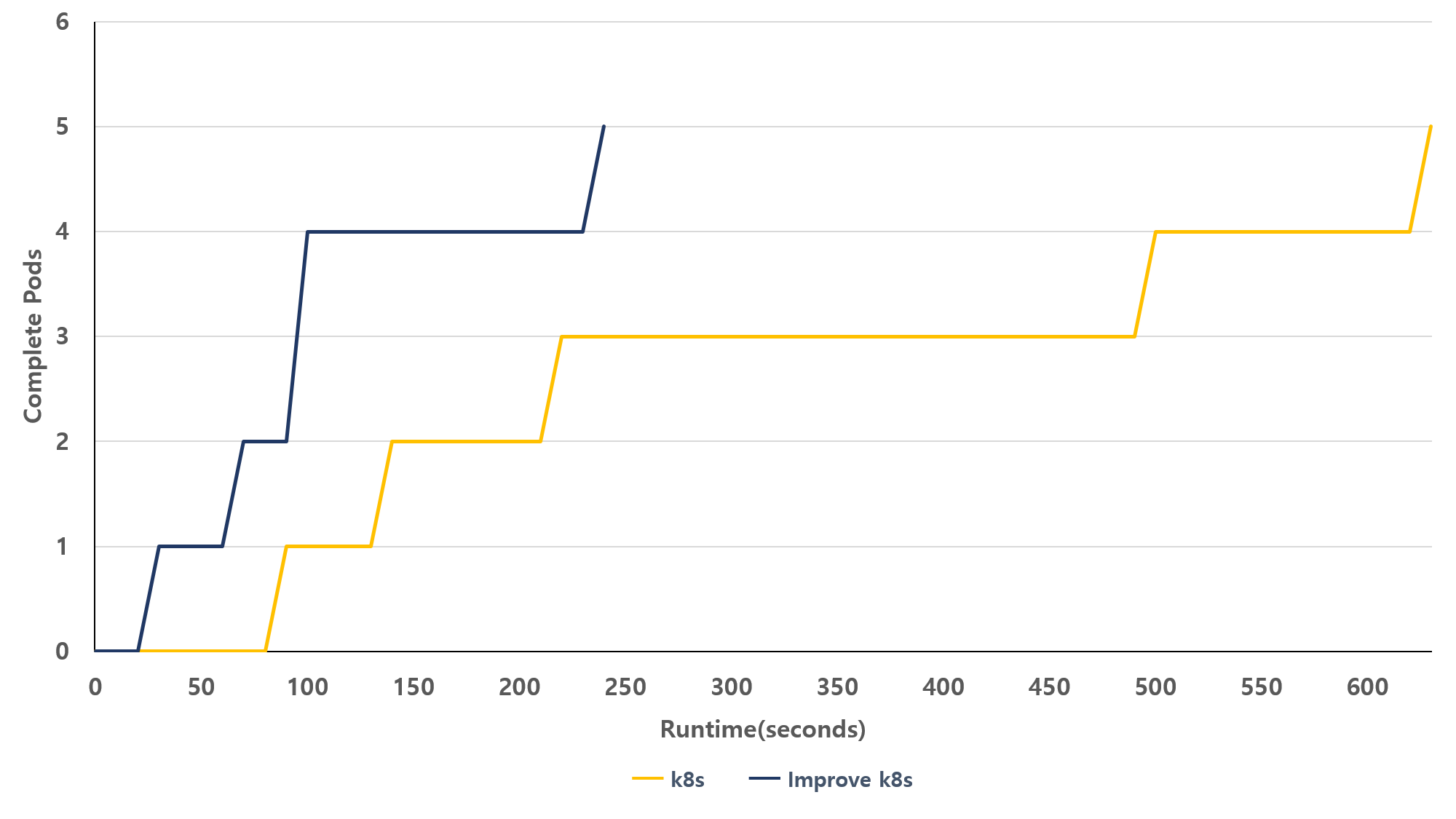 그림 9. 개선 전후 다중 배포 완료 시간
그림 9. 개선 전후 다중 배포 완료 시간
그림 9는 제안된 스케줄링 기법이 배포 후 완료 시간이 얼마나 걸리는지 기존 방식과 비교한 결과이다. 기존 쿠버네티스 방식에서는 다중 파드를 배포하면 수행 시간이 늘어나는 문제가 있음. 파드가 배치되는 워커 노드의 상태가 고려되지 않은 채 배포가 이루어지기 때문이다. 반면 개선된 방식에서는 배포 이전에 각 워커의 현재 상태를 반영하여 자원 배치가 이루어지므로 수행 시간이 상대적으로 짧게 수행된다.
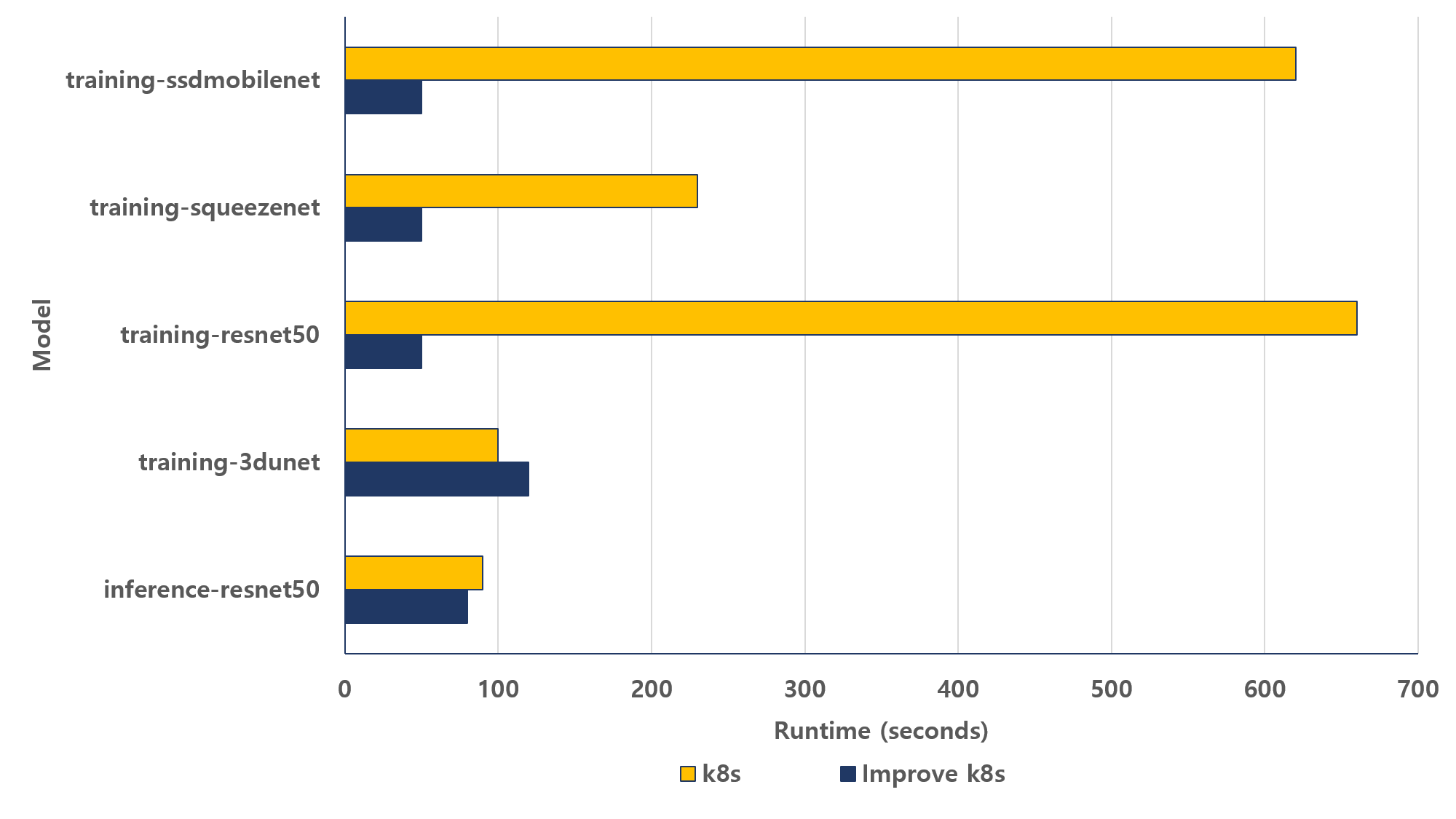 그림 10. 개선 전후 다중 배포 후 모델별 수행 시간
그림 10. 개선 전후 다중 배포 후 모델별 수행 시간
그림 10은 기존 쿠버네티스 방식과 제안된 스케줄링 방식의 수행 시간을 비교한 결과이다. 기존 방식에서는 워커 노드의 자원 상태가 충분히 반영되지 않아 특정 모델에서 수행 시간이 과도하게 증가한다.
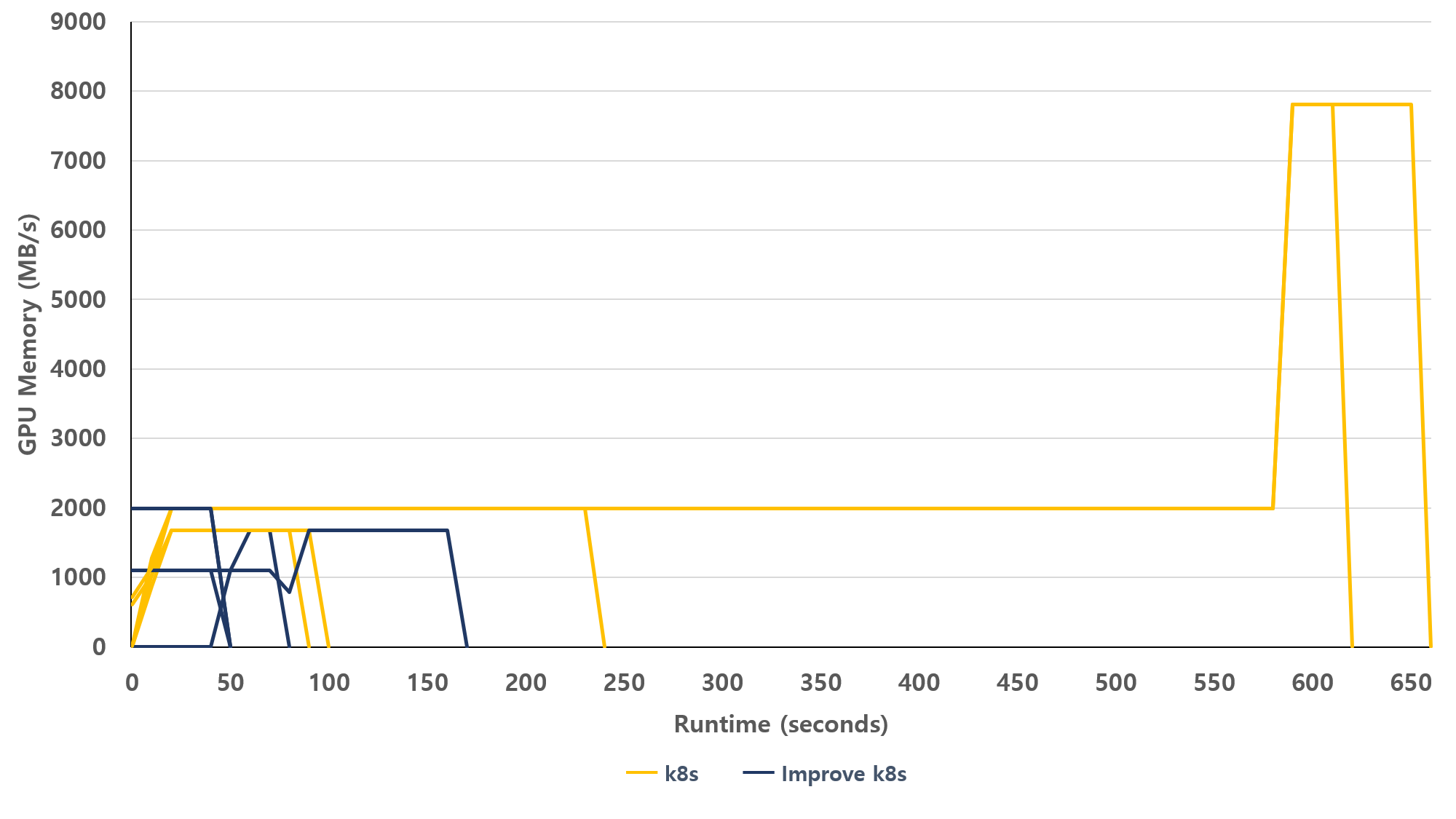 그림 11. 개선 전후 다중 배포 간 GPU 사용률
그림 11. 개선 전후 다중 배포 간 GPU 사용률
그림 11은 GPU 메모리 사용률이 시간에 따라 어떻게 변화하는지를 비교한 결과이다. 개선된 스케줄링 방식(파란색)에서는 파드가 실행되기 전에 워커 노드의 GPU 상태를 분석하여 GPU 자원이 과도하게 집중되지 않도록 분배한다. 그 결과 파드가 실행에 필요한 GPU를 빠르게 확보한 뒤 짧은 시간 내 실행이 종료된다.
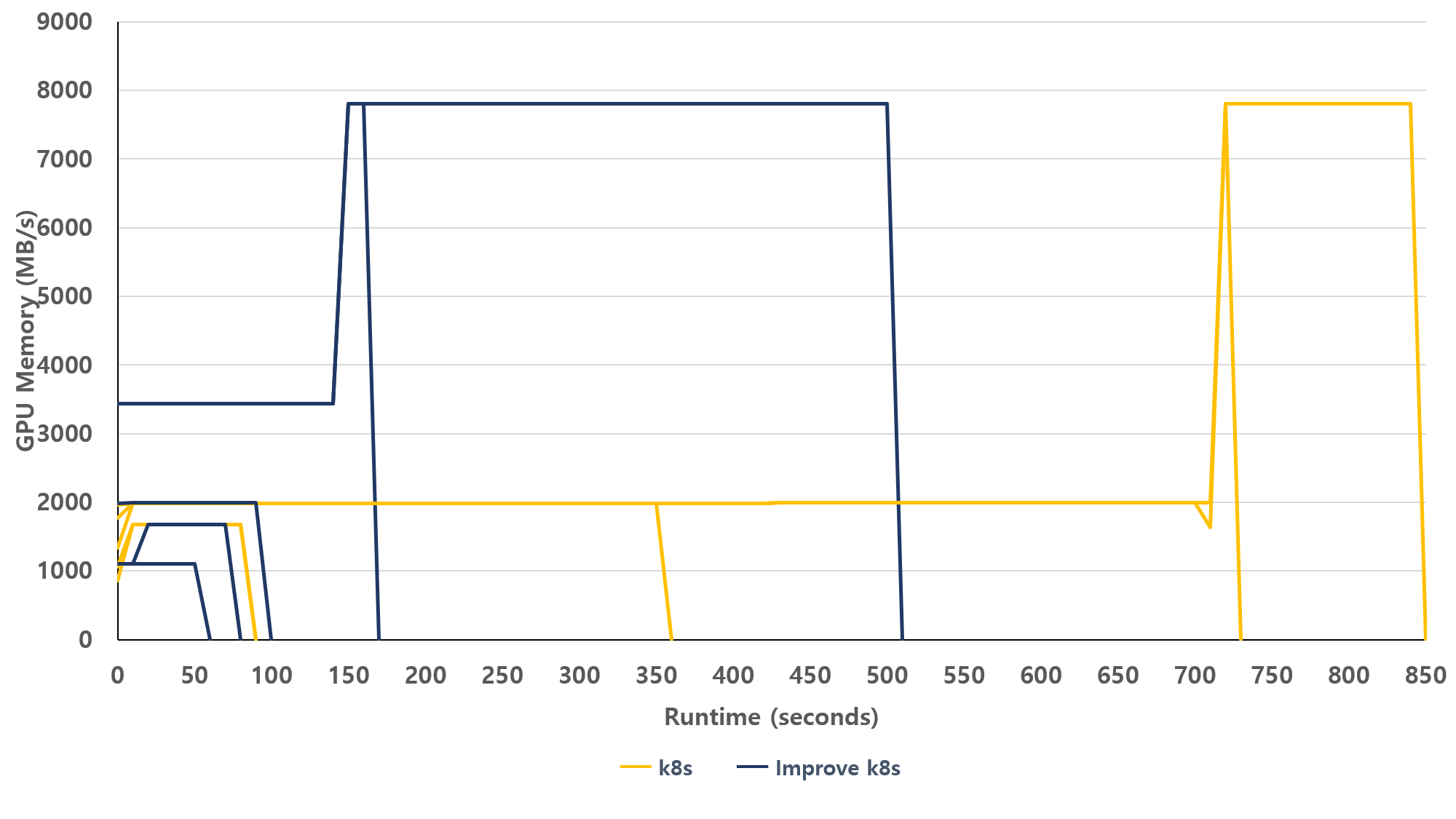 그림 13. 개선 전후 I/O 부하 상황에서 GPU 사용률
그림 13. 개선 전후 I/O 부하 상황에서 GPU 사용률
그림 13은 I/O 부하가 가해진 상황에서 GPU 사용률이 어떻게 변화하는지를 비교한 결과이다 I/O 부하가 없을 때와 비교해서는 개선후 쿠버네티스가 수행시간이 늘어났지만 개선전과 비교하여 상대적으로 짧은 수행시간을 갖는다.
6. 결론
가상화 기반 쿠버네티스 환경에서 AI 워크로드 수행 시 발생하는 GPU, CPU 및 I/O 자원 간의 구조적 불균형 문제를 분석하였다. 자원 인지형 스케줄링 기법을 제안하고 검증한다. 제안 기법은 다중 파드 환경에서 GPU 부하가 균등하게 분산되었고, I/O 부하 환경에서도 워크로드 간 실행 흐름이 상대적으로 일정하게 유지되었다. GPU 메모리 점유율의 상승 패턴은 보다 완만하고 안정적으로 형성되었으며 전체 수행 시간 감소시킬 수 있었다.
2. VDO 기반 중복제거 파일시스템의 성능 분석
1. 서론
중복제거는 저장되는 데이터에서 중복된 블록을 탐지하여 제거하는 방식으로, 저장용량을 실질적으로 개선하는 데 큰 효과를 보이는 기술이다. 특정 AI 워크로드에서는 동일하거나 유사한 구조의 데이터가 여러 단계에 걸쳐 반복해서 생성, 변경, 저장되는 경향이 있어 데이터 중복률이 높게 나타난다. 중복제거 기술은 저장 공간 효율을 극대화할 수 있으나, 추가 연산 오버헤드로 인한 성능 저하 가능성이 존재한다. 본 연구는 여러 중복제거 파일시스템 중 VDO(Virtual Data Optimizer)에 초점을 맞춘다.
- 중복제거 파일시스템 비교
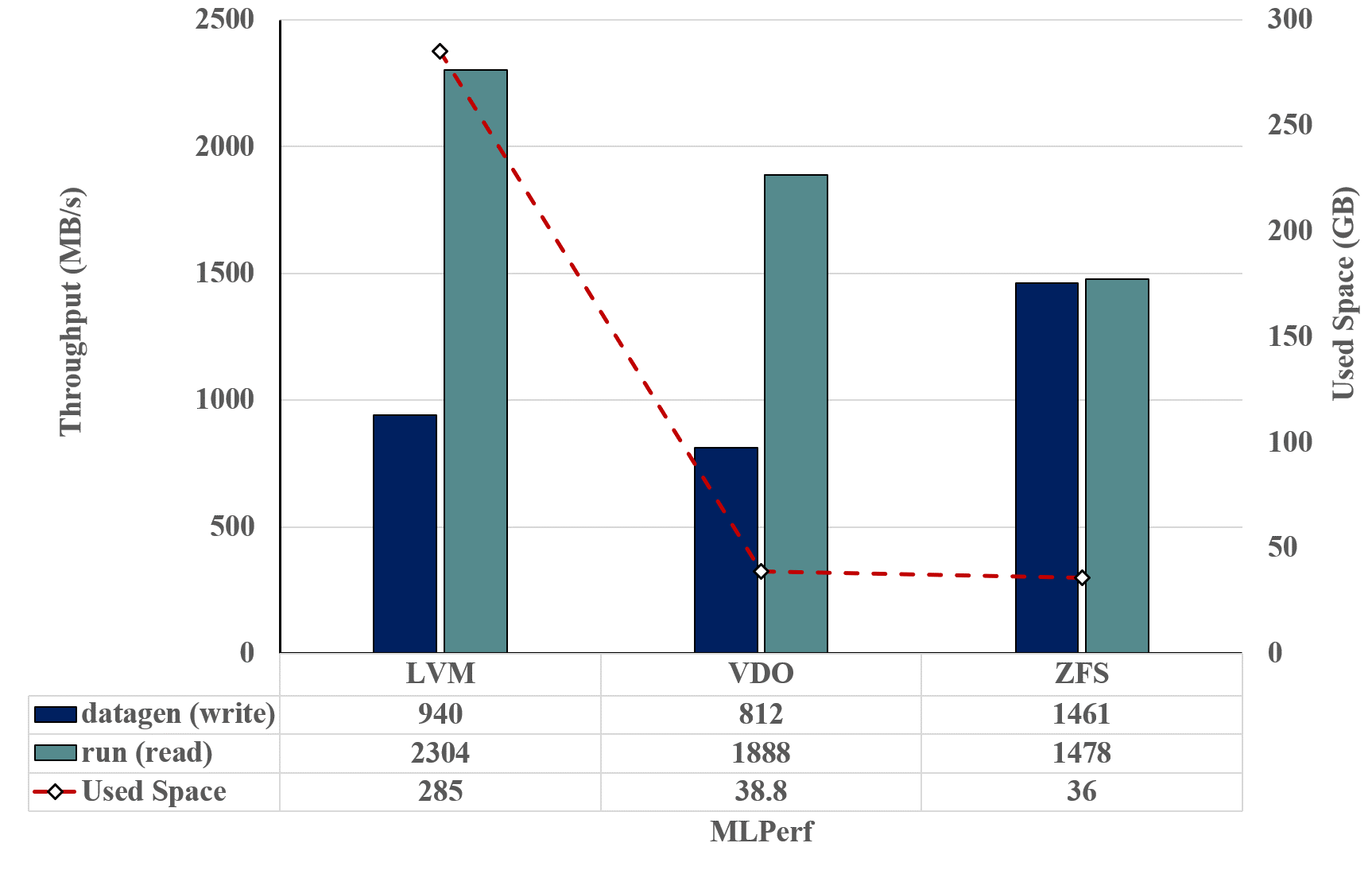 그림 14. MLPerf 벤치마크에서 파일시스템 성능 및 스토리지 사용률 비교
그림 14. MLPerf 벤치마크에서 파일시스템 성능 및 스토리지 사용률 비교
그림 14는 MLPerf Storage 벤치마크 테스트 중 3D-UNet 모델을 활용하여 LVM, VDO, ZFS를 비교한 결과이다. MLPerf의 측정 구간은 크게 datagen(write 중심)과 run(read 중심) 단계로 구성된다. 실험 결과 LVM 대비 VDO와 ZFS는 datagen 및 run 처리 속도에서 상대적으로 큰 성능 손실이 나타나지 않으나 저장 공간 측면에서는 상당히 유용한 부분을 알 수 있다.
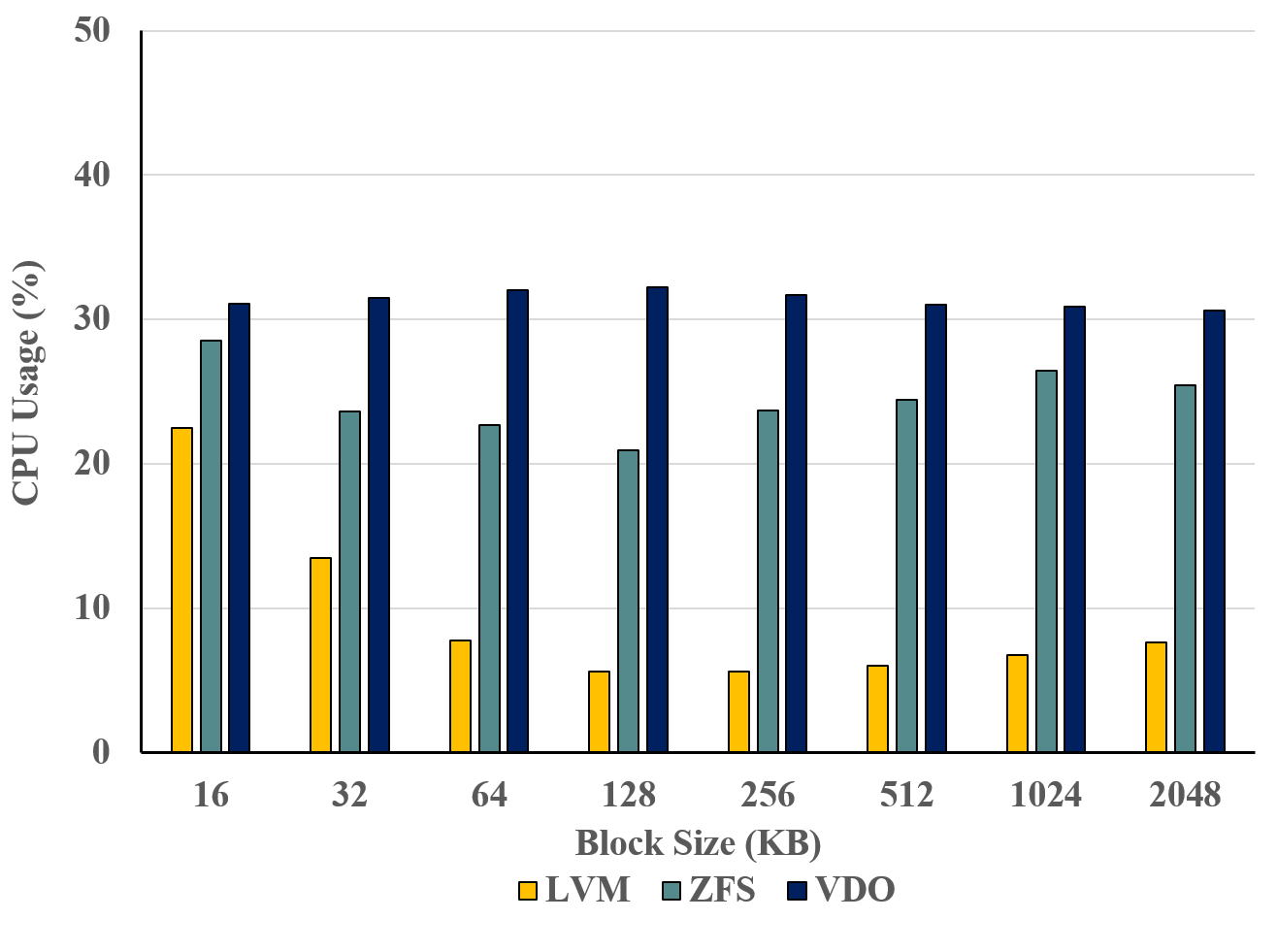 그림 15. LVM, ZFS, VDO 파일시스템의 CPU 사용률 비교
그림 15. LVM, ZFS, VDO 파일시스템의 CPU 사용률 비교
그림 15는 LVM, ZFS, VDO 세 가지 파일시스템에서 I/O 작업을 수행할 때의 CPU 활용도를 비교한 결과이다. 중복제거 기능이 적용된 VDO와 ZFS는 비중복 파일시스템인 LVM보다 CPU 점유율이 높은 것을 알 수 있다.
3. VDO 성능 분석
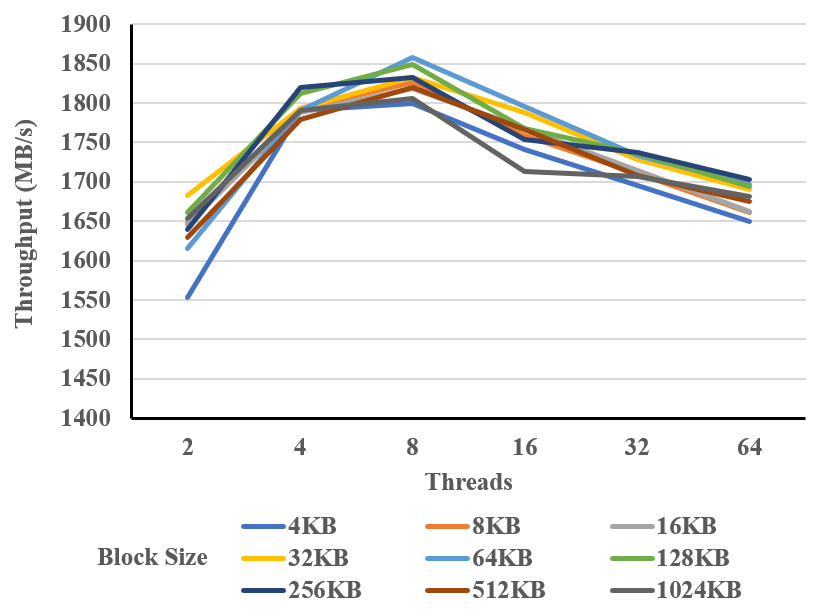 그림 16. 블록 크기와 스레드 개수에 따른 성능 그래프
그림 16. 블록 크기와 스레드 개수에 따른 성능 그래프
그림 16은 블록 크기와 스레드 수가 VDO의 처리 성능에 어떤 변화를 주는지 분석한 결과이다. 블록 크기나 스레드 개수와 같은 스토리지의 전통적인 변수들은 VDO에서 큰 성능 변화를 유발하지 않는 것을 알 수 있다.
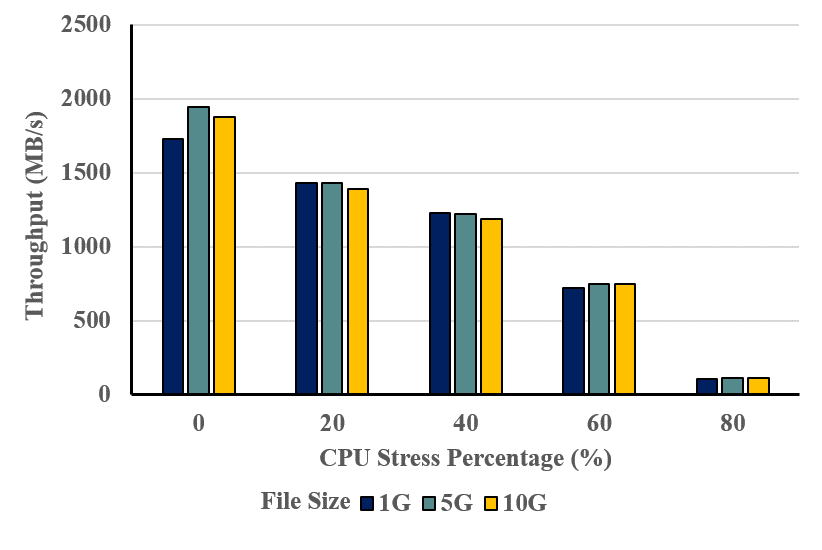 그림 17. CPU 사용률 별 FIO를 사용한 성능 비교
그림 17. CPU 사용률 별 FIO를 사용한 성능 비교
VDO 성능에 영향을 주는 요소를 보다 명확하게 파악하기 위해, CPU 자원을 의도적으로 소모 시키는 상황에서 추가 실험을 수행하였다. 그림 17의 테스트에서는 stress-ng 도구를 활용하여 시스템 전체에 강한 연산 부하를 발생시킨 뒤 FIO를 이용해 VDO의 처리 성능 변화를 측정하였다. CPU 점유율이 높아질수록 처리량이 빠르게 감소하는 경향이 나타나 중복제거 과정이 CPU에 크게 의존하는 특성을 확인할 수 있다.
 그림 19. VDO의 흐름도
그림 19. VDO의 흐름도
그림 19는 VDO의 중복제거 흐름을 도식화한 것이다.
- 전달된 데이터를 4KB 단위의 블록으로 나누는 작업
- 각 블록이 제로 블록인지 판별
- 제로 블록인 경우 참조 카운트만 증가
- 제로 블록이 아닌 경우 해시 알고리즘을 적용해 블록을 고유한 해시 값으로 변환
- 새로 생성된 해시 값을 메모리에 유지되는 인덱스 테이블과 비교해 동일한 값이 존재하는지를 확인
- 이미 인덱스에 존재하는 해시 값인 경우 참조 카운트만 증가
- 없는 경우 신규 항목으로 등록하고 실제 데이터 블록을 스토리지에 기록
- 슈퍼 블록을 갱신
4. 중복제거 성능 분석
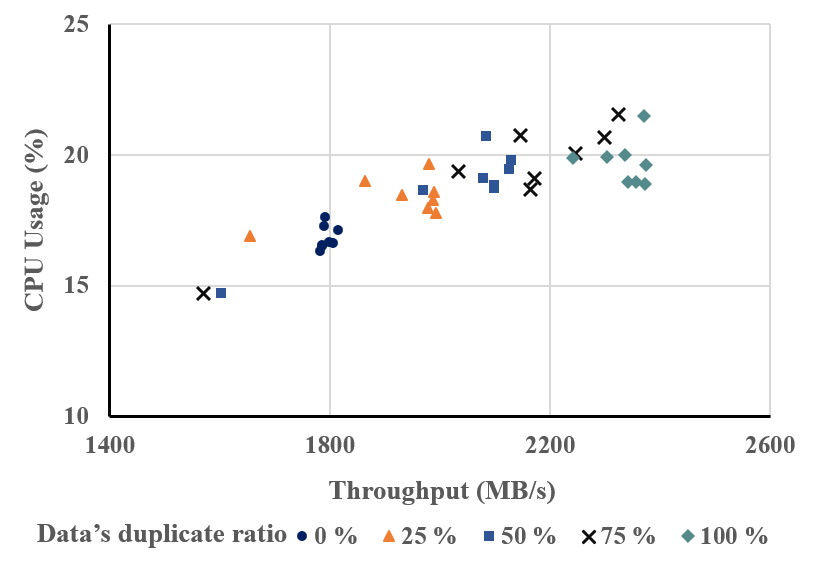 그림 22. 중복된 데이터의 비율에 따른 성능 및 CPU 사용률 분포도
그림 22. 중복된 데이터의 비율에 따른 성능 및 CPU 사용률 분포도
그림 22는 중복 비율 변화에 따른 I/O 성능과 CPU 사용률까지 함께 비교한 그래프이다. 데이터의 중복율이 높아질수록 I/O 처리 성능은 향상된다. 하지만 CPU 사용률은 오히려 증가한다. 중복제거 파일시스템의 구조적 특성 때문으로, 중복된 데이터를 저장하지 않는 대신 인덱스 갱신 작업이 빈번하게 발생하기 때문이다.
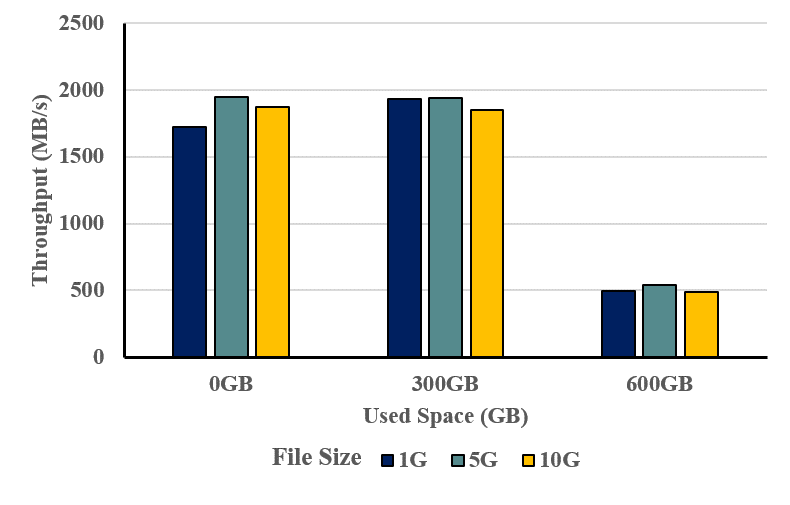 그림 23. 스토리지 공간 사용량에 따른 성능 비교
그림 23. 스토리지 공간 사용량에 따른 성능 비교
그림 23은 VDO에서 스토리지 사용량이 증가할 때 I/O 성능이 어떤 변화를 보이는지를 실험한 결과이다. 약 300GB 수준까지는 처리 속도가 일정 부분 향상되는 모습을 확인할 수 있다. 스토리지 사용량이 300GB를 넘어 600GB 수준에 이르자 성능이 떨어지는 현상 확인된다. 저장된 데이터가 많아질수록 인덱스 탐색 범위가 넓어지고 비교 작업도 복잡해져 CPU, 메모리 부담이 함께 증가하게 된다.
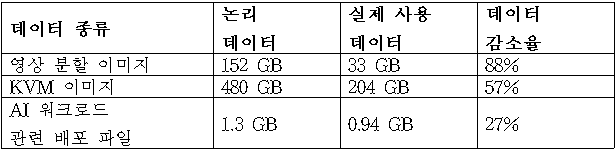 표 6. AI 관련 데이터의 데이터 감소율
표 6. AI 관련 데이터의 데이터 감소율
표 6은 중복제거 파일시스템 적용 시 AI 워크로드 데이터의 저장 효율을 비교한 결과를 나타낸다. 영상 분할 이미지와 쿠버네티스 워커 이미지는 구조적 유사성으로 인해 높은 중복제거율을 나타냈다. AI 모델 및 배포 파일 역시 버전 간 유사성과 데이터 반복 사용으로 유의미한 저장 공간 감소가 확인되었다.
5. 중복제거 환경에서 스케줄링 비교
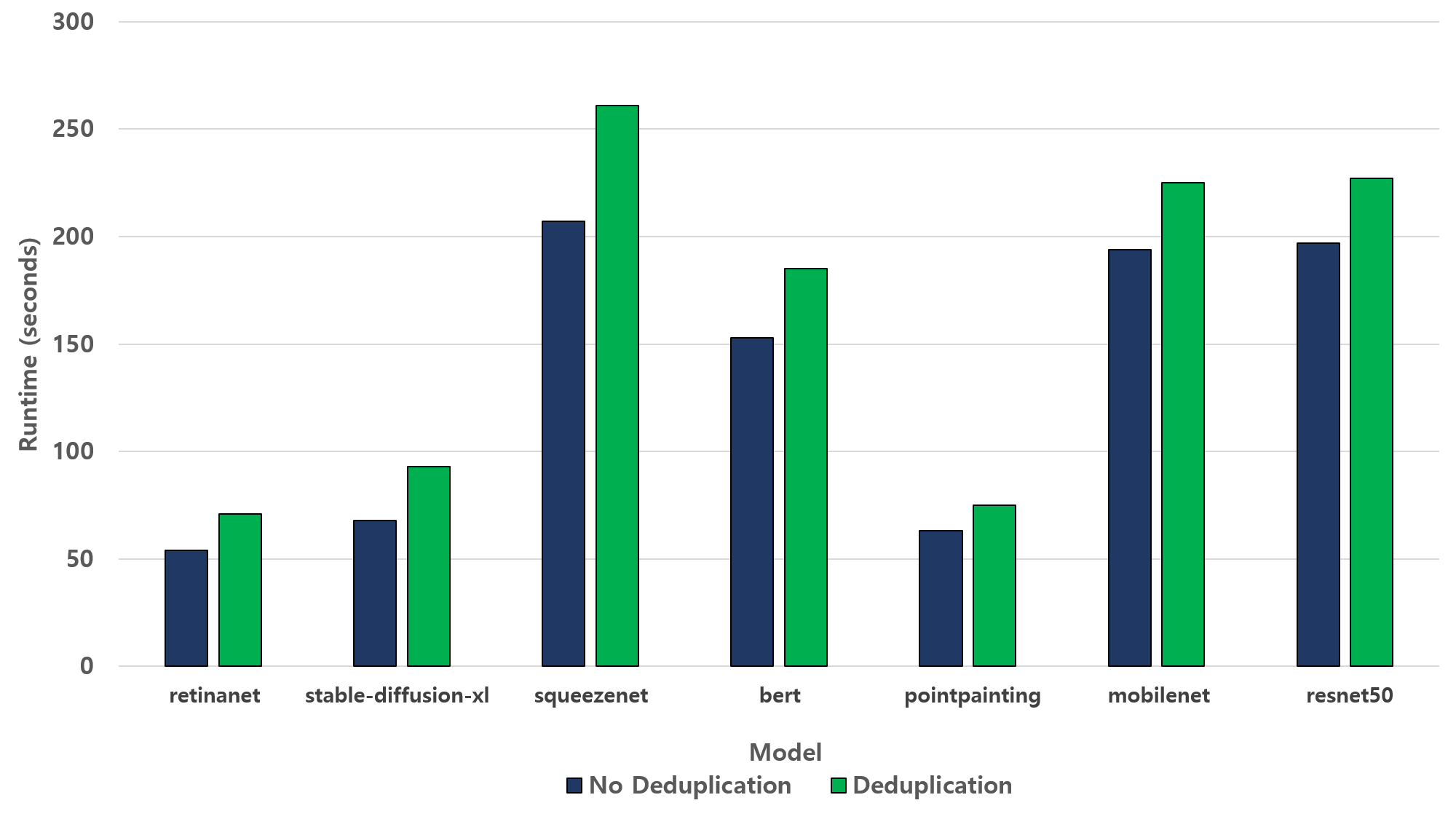 그림 24. 중복제거 환경에서 수행 시간 비교
그림 24. 중복제거 환경에서 수행 시간 비교
그림 24는 추론 7개 모델을 개선된 쿠버네티스 기법을 사용하여 배포했을 때 중복제거 환경과 아닌 환경의 수행 시간을 나타낸 결과이다. 전체적으로 중복제거 기능이 활성화되면 블록 처리와 해시 계산에 따른 추가 연산이 발생하여 수행 시간이 일정 수준 증가한다. 그러나 기존 쿠버네티스 방식의 성능 저하와 비교하면 상대적으로 적다고 볼 수 있다.
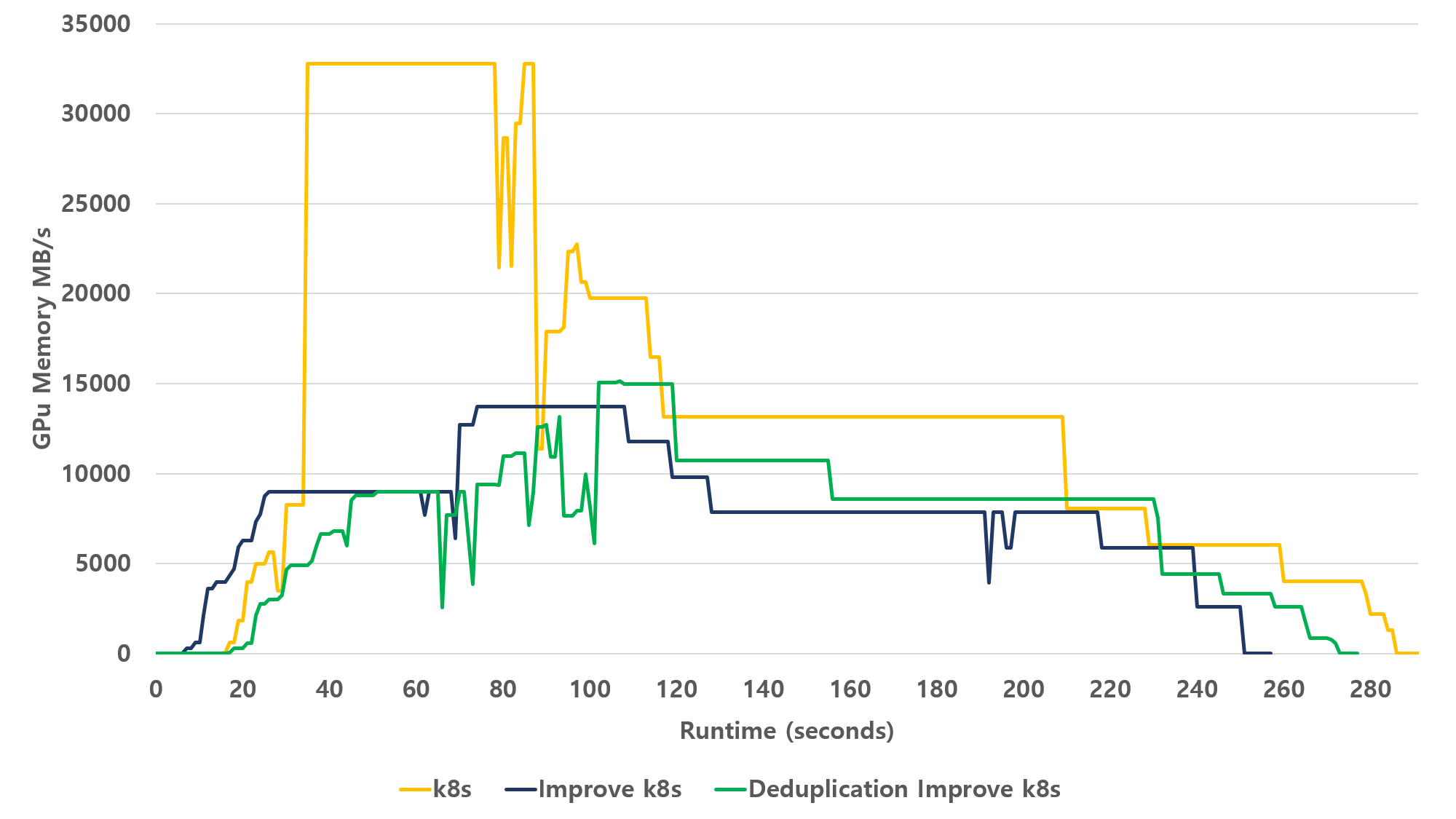 그림 25. 중복제거 환경에서 GPU 사용량 비교
그림 25. 중복제거 환경에서 GPU 사용량 비교
그림 25는 개선 전 쿠버네티스, 개선된 쿠버네티스, 중복제거 환경에서 개선된 쿠버네티스를 사용하여 GPU 사용량을 측정한 테스트 결과이다. 전체적인 패턴을 보았을 때 중복제거가 없는 상황의 개선된 쿠버네티스보다는 수행시간이 늦게 끝나지만 시간별 GPU 사용량 패턴은 유사함을 보인다. 중복제거로 인한 오버헤드 때문에 성능이 저하된 것은 맞지만 개선 전의 쿠버네티스와 비교하였을 때 더 낮은 GPU 사용량과 더 짧은 수행시간을 보인다. 저장 공간 측면에서 높은 이점을 제공하는 동시에, 개선된 스케줄링 기법이 GPU 대기 문제를 완화하여 중복제거 오버헤드의 부정적 영향을 보완할 수 있다.
6. 결론
VDO를 비롯한 중복제거 파일시스템에서 성능 저하가 발생하는 원인을 다양한 측면에서 분석하였다. 분석 결과 중복제거 기술 자체는 저장 공간 활용도를 높이는 데 매우 효과적이지만, 실제 성능 저하를 유발한다. 중복제거 파일시스템이 적용된 환경에서도 앞에서 제안된 스케줄링 기법의 이점이 어느 정도 유지됨을 확인할 수 있다.