제 7회 난공불락 인프라 세미나
by 권 진영 (gc757489@gmail.com)
난공불락 인프라 세미나를 준비하면서 …
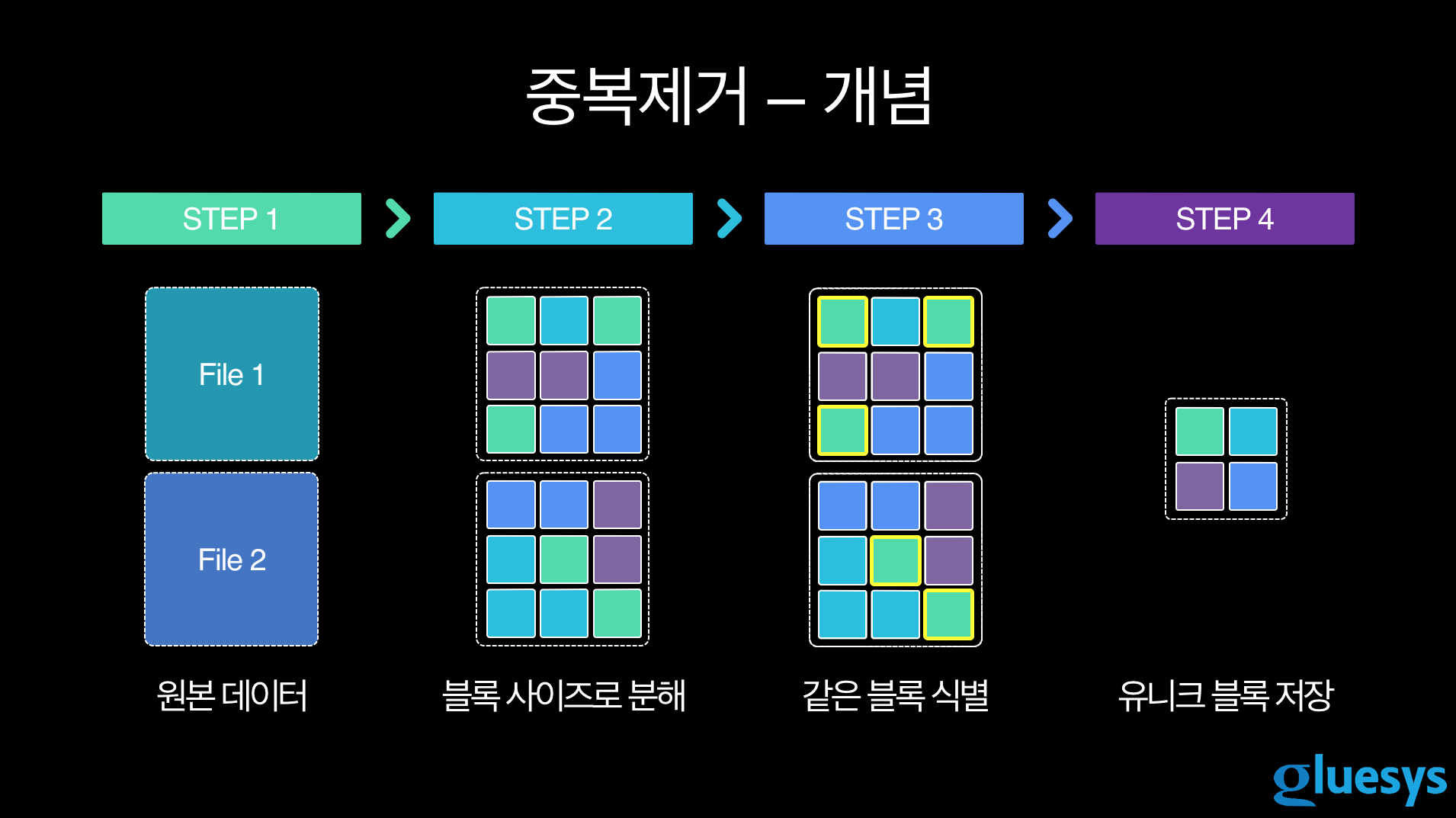
안녕하세요 글루시스 시스템 개발자 권진영입니다. 지난해 12월 난공불락 세미나에서 dm-vdo(이하 VDO)를 소개해 보았습니다. VDO(Virtual Data Optimizer)는 Red Hat 리눅스에서 데이터 압축 및 중복제거를 수행하는 툴입니다. 중복제거란 데이터를 블록 단위로 나누어서 중복되는 블록 중 하나만 저장하는 기술로 실제 저장되는 데이터를 극단적으로 줄일 수 있습니다.
이번 세미나에서 제가 중복제거에 대해 코끼리를 냉장고에 집어넣는 방법이라는 유머로 비유해 봤는데요, 제가 이 기술을 처음 알았을 때 이 유머가 정말 현실이 되는 듯한 느낌을 받았었습니다.
VDO는 스토리지에서 데이터의 중복을 제거하는 기술인데 데이터를 블록 단위로 쪼개서 중복되는 블록은 단 한 개만 저장하는 기술이라 실제 저장되는 블록을 상황에 따라 극단적으로 줄일 수도 있는 기술이죠.
이처럼 VDO에 매력을 느기고 이것저것 테스트해 보는 와중에 한국 리눅스 사용자 그룹의 세미나 모집 소식을 듣게 되었습니다.
당시는 입사한 지 아직 1년이 채 되지 않았던 터라 다른 베테랑 개발자들 앞에서 발표하기 부담되어 고민하던 중에 같이 발표를 진행한 김지현 책임연구원님의 도움으로 준비를 시작하게 되었습니다.
기존에 진행했던 테스트 결과를 취합하고 결과 및 사용법을 정리하는 과정은 순조로웠지만, 막상 주요 내용을 전달하기 위해 VDO 커널 코드를 이해하고 정리하는데 생각보다 많은 시간이 들었습니다.
커널 코드를 분석하면서 흐름이나 기본적인 구조는 파악이 됐지만, 아직도 준비해야 하는 부분이 너무 많아 막막할 때 많은 분이 개인 시간을 할애해서 코드에 대해 가이드 및 분석 등 정말 많은 도움을 주셨습니다.
그렇게 발표 직전까지 같이 달려주어서 어찌어찌 발표 준비를 마무리할 수 있었습니다.
난공불락 인프라 세미나중에 …
발표 준비를 마친 당일인 2019년 12월 14일에 한국 리눅스 사용자 그룹이 주관하는 난공불락 인프라 세미나에 참가했습니다.
이 세미나는 리눅스 사용자들끼리 모여서 기술적인 지식을 공유하는 세미나로 누구나 참석할 수 있고 세미나 모집 중에 발표를 신청하면 누구나 자신의 지식을 공유할 수 있습니다.
그러다 보니 매번 다른 주제들로 세미나가 구성되는데 이번에는 스토리지 시장동향, 네이버 클라우드 플랫폼, Ceph, GlusterFS와 제가 준비한 VDO까지 스토리지에 관한 주제들이 많은 세미나로 진행되었습니다.

처음은 ISBC 대표님이신 김완희 님께서 Market trend Storage Cloud라는 주제로 시작해주셨습니다.

두 번째 세션은 NBP에서 Tech Evangelist를 맡고 계신 송창안 님이 발표를 해주셨습니다. 발표가 끝난 이후 쉬는 시간을 통해 네이버 클라우드 플랫폼을 사용할 수 있는 쿠폰을 받을 수 있었습니다.

드디어 제 차례가 와버려서 3번째 세션에 앞서 말씀드린 VDO에 대해서 소개하는 발표를 진행하였습니다.
아래 첨부한 PPT와 사용법 영상을 활용해서 발표를 진행했습니다.


발표에서 VDO의 주요 기능, 구조, 사용법, 관련된 이슈들을 위주로 소개를 진행하였는데 졸업 후 처음 발표를 해본 탓인지 정말 많이 긴장해서…. 발표 처음 도입 부분은 잘 시작한 거 같은데 점점 더 긴장돼서 벌벌 떨면서 발표를 한 것 같습니다.
심지어 뒷부분에서는 시연 영상이 잘 안 되면서 머리가 하얘지기까지 했지만, 김지현 책임연구원님의 도움으로 전달하고자 했던 내용은 모두 전달할 수 있었습니다.
발표 후 Q&A 시간에 받은 질문을 몇 가지 추려서 다음과 같이 정리해보았습니다.
Q. 현재 VDO에 대해 액티브하게 개발 중인지 안정화돼서 더 이상 개발을 하지 않는지 알고 싶습니다
A. Permabit에서 오랜 기간 동안 개발하던 프로젝트를 Red Hat에서 인수한 거라 안정성 자체는 높다고 볼 수 있습니다.
Q. 파일 셋들이 다양할 텐데 어떤 형태의 파일들이 중복제거가 잘되는지 알고 싶습니다.
A. 테스트를 통해 확인했을 때 VM이나 컨테이너의 경우 가장 높은 중복제거율을 볼 수 있었고 그림 파일, 오피스파일 등에서는 낮은 중복제거율을 볼 수 있었습니다.
Q. VM, 컨테이너의 경우에 중복제거율이 높다고 해주셨는데 예를 들어 VM을 100G로 생성하여도 동적 할당에 의해 실제 사용되는 부분은 10G 정도이기도 하고 또 여러 가지 케이스가 아니라 비슷한 경우의 패턴이기 때문에 중복제거율이 높은 게 아닌가요
A. 어느 정도 그런 부분이 있는 건 사실이지만 VM에 사용하는 OS들의 기본 프리셋이 겹치기 때문에 다른 경우보다 중복제거율이 높은 것으로 보입니다.
Q. 레이어가 추가되면 될수록 효율이 떨어질 텐데 앞의 그래프를 보면 효율이 높아지는 것으로 보여서 설명을 부탁드립니다.
A. 그래프를 보면 성능 면에서는 떨어진 것을 확인할 수 있습니다. 성능의 경우에는 30~40%의 성능 저하가 발생하지만, 튜닝하면 약 20% 정도로 성능 저하를 막을 수 있을 것으로 보입니다.
질의응답은 제가 아닌 김지현 책임연구원님이 진행하셨지만 다양한 질문이 덕분에 모르던 부분에 대해서 다시 한번 생각할 수 있었습니다.
Q&A가 끝난 후에는 대한 CNI의 이미옥 님이 Ceph에 관해서, 대한 CNI의 우종현 님이 GlusterFS에 관한 발표를 해주셨습니다.


난공불락 인프라 세미나를 마치고 …
제 세션의 발표를 끝내고 나서는 끝났다는 안도감과 행복이 있었지만, 한편으로는 잘하지 못해서 후회도 되고 왜 더 준비하지 못했는지 자책하기도 했습니다. 그래도 시간이 지난 지금에 와서 보니 그때의 경험은 저 자신을 바꿀 수 있었던 귀중한 기회라 생각됩니다. 포기했었다면 얻을 수 없던 지식, 이룰 수 없었을 뿌듯함이 아직도 저를 지탱해줍니다.
개발자들은 대부분 각자의 주관이 강하다고 생각하는 편이라
이런 걸 해보면 어떨까요? 라는 제의를 하면
싫은데요? 혹은 무응답 이 예상되지만
그래도 자신의 두려움에 도전해보는 건 어떨까요?
막내 연구원의 발표를 위해 많은 도움을 주신 김경표 소장님, 김지현 책임연구원님, 김태훈 선임연구원님께 감사의 말씀 드립니다.